

Vector databases are the invisible engine behind modern AI experiences—from ChatGPT-style assistants that understand your questions to Netflix recommendations that know your taste. Unlike traditional databases that match exact words, vector databases understand meaning. This guide explains what they are, why they matter, and how businesses are using them to build smarter applications—all without technical jargon.
The Problem with Traditional Search
You've experienced this frustration before.
You search your company's document system for "employee vacation policy" and get nothing. But the document exists—it's just called "Annual Leave Guidelines." Traditional search failed because it looks for exact word matches, not meaning.
Or consider your customer support system. Someone asks "How do I reset my password?" but your knowledge base article is titled "Account Recovery Steps." Traditional keyword search misses the connection entirely.
This is the fundamental limitation of how computers have searched for information for decades: they match letters and words, not concepts and meaning.
Vector databases solve this problem. They understand that "vacation" and "annual leave" mean the same thing. They know that "reset password" and "account recovery" are related concepts. They search by meaning, not just matching text.
What Is a Vector Database? (The Simple Explanation)
Imagine you're organizing a music collection. Traditional databases would file songs by exact attributes: artist name, album title, release year. To find a song, you'd need to know exactly what you're looking for.
A vector database works differently. It understands the feel of each song—is it upbeat or melancholy? Acoustic or electronic? High energy or relaxing? When you ask for "something like that jazz song from the coffee shop," it can find songs that feel similar, even if they share no obvious attributes.
In technical terms:
A vector database stores information as mathematical representations called "vectors" or "embeddings." These vectors capture the meaning and relationships within data—text, images, audio, or any content—allowing the database to find things that are conceptually similar, not just textually identical.
The key insight: Two pieces of content can be similar in meaning even when they share no words in common. Vector databases understand this.
Why Does This Matter Now?
Vector databases aren't new, but they've become essential infrastructure for one reason: the AI revolution.
The Rise of AI Applications
When ChatGPT launched in late 2022, it demonstrated what large language models (LLMs) could do. But these models have a critical limitation—they only know what they were trained on. They can't access your company's documents, your product catalog, or your customer history.
Vector databases bridge this gap. They allow AI applications to:
- Search your private data by meaning
- Retrieve relevant context to answer questions accurately
- Maintain long-term memory across conversations
- Provide recommendations based on conceptual similarity
Market Growth Reflects Business Demand
The numbers tell the story:
- USD 2.2 billion: Vector database market size in 2024
- 21.9% annual growth: Projected through 2034
- 30% of enterprises: Expected to adopt vector databases by 2026 (Gartner)
- 55.2 billion visits: To AI chatbots from April 2024 to March 2025
Businesses aren't adopting vector databases because they're trendy—they're adopting them because AI applications simply don't work well without them.
How Vector Databases Work (Without the Math)
Let's break down the process into understandable steps:
Step 1: Converting Content to Vectors
First, content goes through an AI model that converts it into a vector—a list of numbers that represents its meaning.
Think of it like creating a detailed profile for each piece of content:
| Content | Traditional Index | Vector Representation (Simplified) |
|---|---|---|
| "The quarterly sales exceeded targets" | Keywords: quarterly, sales, exceeded, targets | Meaning: business performance, positive outcome, financial metrics, time-based reporting |
| "Revenue growth surpassed expectations" | Keywords: revenue, growth, surpassed, expectations | Meaning: business performance, positive outcome, financial metrics, success indicator |
Notice how the traditional index sees completely different words, but the vector representation captures that both sentences express similar concepts.
Step 2: Storing Vectors Efficiently
Vector databases use specialized methods to organize these mathematical representations so similar items are grouped together. This allows for incredibly fast searching—finding related content among millions of items in milliseconds.
Step 3: Finding Similar Meanings
When you search, your query is also converted to a vector. The database then finds stored vectors that are closest to your query vector—not by matching words, but by measuring similarity in meaning.
Example in action:
You search: "shoes for rainy weather"
Traditional search returns: Only items containing "shoes," "rainy," and "weather"
Vector search returns: Waterproof boots, rain-resistant sneakers, rubber-soled footwear, galoshes—items that match the intent of your search, even without those exact words.
The Difference That Matters: Keywords vs. Meaning
| Aspect | Traditional Database Search | Vector Database Search |
|---|---|---|
| How it works | Matches exact words and phrases | Understands concepts and relationships |
| Search for "car repair" | Returns only documents with "car repair" | Also finds "automobile maintenance," "vehicle servicing," "auto mechanic guides" |
| Handles synonyms | Requires manual configuration | Automatic—understands words mean the same thing |
| Understands context | No—treats all words equally | Yes—knows "apple" means different things in tech vs. fruit contexts |
| Typos and variations | Usually fails | Often succeeds—captures meaning despite spelling |
| Cross-language potential | Requires separate indexes | Can find similar meaning across languages |
| Speed at scale | Fast for exact matches | Fast for similarity across millions of items |

Real Business Applications
Vector databases power experiences you likely use daily without realizing it.
1. AI Chatbots and Virtual Assistants
The challenge: ChatGPT and similar AI models are knowledgeable but generic. They don't know about your products, policies, or customers.
The solution: Retrieval-Augmented Generation (RAG)—a technique where AI chatbots search a vector database to find relevant information from your data before responding.
How it works:
- Customer asks: "What's your return policy for electronics?"
- Vector database searches your policy documents by meaning
- Relevant policy sections are retrieved
- AI generates an accurate, specific answer based on your actual policies
Business impact: Companies using RAG-powered chatbots report 40% reductions in customer support costs and 85% improvements in response relevance. The AI doesn't hallucinate answers—it's grounded in your real data.
2. Semantic Enterprise Search
The challenge: Employees waste hours searching for information across documents, emails, wikis, and systems. Studies suggest knowledge workers spend 20% of their time just looking for information.
The solution: Vector-powered search that understands what employees are actually looking for.
Example scenarios:
| Employee Searches For | Traditional Search Finds | Vector Search Finds |
|---|---|---|
| "client onboarding process" | Documents with those exact words | Also: "new customer setup guide," "account activation procedures," "getting started with clients" |
| "marketing budget Q3" | Only exact matches | Also: "Q3 promotional spending," "third quarter advertising allocation," "summer campaign costs" |
| "competitor pricing" | Limited results | Also: "market rate analysis," "competitive landscape pricing," "industry price benchmarks" |
Business impact: Faster decision-making, reduced duplicate work, and employees who can actually find institutional knowledge.
3. Product Recommendations
The challenge: Customers don't always know exactly what they want, and they certainly don't use your product naming conventions.
The solution: Recommendations based on conceptual similarity, not just purchase history or category matching.
How streaming platforms use this:
- Netflix doesn't just recommend "other comedies"—it understands the type of humor, pacing, and themes you enjoy
- Spotify suggests songs that feel similar, even across different genres
- Amazon finds products related to your interests, not just items other people bought
Business impact: Higher engagement, better conversion rates, and customers who feel understood rather than sold to.
4. Customer Support Intelligence
The challenge: Support teams answer the same questions repeatedly, and finding past solutions requires knowing the exact terminology.
The solution: Vector search across support tickets, knowledge bases, and conversation histories.
Capabilities:
- Find similar past issues even when described differently
- Surface relevant knowledge base articles for agents automatically
- Identify trends by clustering semantically similar complaints
- Route inquiries to specialists based on meaning, not keywords
Business impact: Faster resolution times, consistent answers, and support teams who learn from collective experience.
5. Fraud Detection and Security
The challenge: Fraudulent activity doesn't always match predefined patterns. Attackers constantly change tactics.
The solution: Represent "normal" behavior as vectors and identify anomalies—transactions or activities that are meaningfully different from established patterns.
Applications:
- Financial fraud detection
- Network intrusion identification
- Identity verification
- Insurance claim analysis
Business impact: Catch novel threats that rule-based systems miss, while reducing false positives.
6. Content Discovery and Management
The challenge: Organizations create enormous volumes of content—documents, images, videos—that becomes impossible to organize or find.
The solution: Automatic organization based on meaning, not manual tagging.
Capabilities:
- Find visually similar images across millions of photos
- Identify duplicate or near-duplicate content
- Cluster documents by topic automatically
- Surface relevant content based on context
Business impact: Marketing teams find assets faster, legal teams locate relevant precedents, and content isn't lost in growing archives.
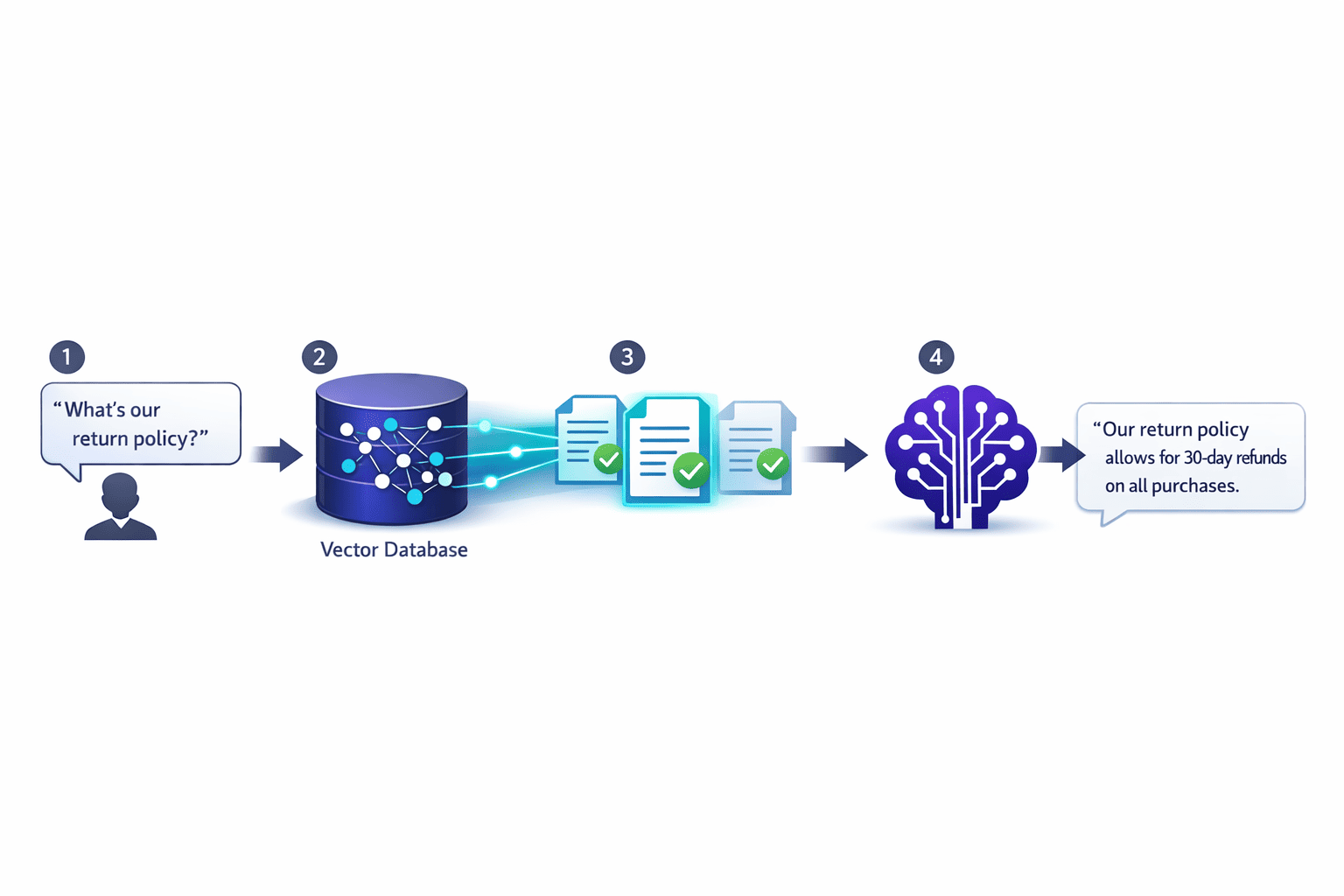
How AI Chatbots Use Vector Databases (RAG Explained Simply)
You've likely heard of "RAG" (Retrieval-Augmented Generation). It's the technique that makes AI chatbots actually useful for business. Here's how it works:
The Problem RAG Solves
Large language models like GPT-4 or Claude have a knowledge cutoff—they were trained on data up to a certain date and know nothing about your specific business.
Ask ChatGPT about your company's vacation policy, and it will either refuse to answer or make something up (hallucinate). Neither is helpful.
How RAG Works
Step 1: Prepare Your Knowledge Your documents, FAQs, policies, and product information are converted into vectors and stored in a vector database.
Step 2: User Asks a Question "What's the process for requesting time off?"
Step 3: Find Relevant Context The vector database searches your knowledge base by meaning and retrieves the most relevant documents—your actual time-off policy, request procedures, and approval workflows.
Step 4: Generate Accurate Answer The AI receives both the user's question and the retrieved context. It generates an answer grounded in your real documentation, not its general training.
The result: Accurate, specific answers that reflect your actual policies and information—not generic responses or hallucinations.
Why Businesses Love RAG
| Benefit | Explanation |
|---|---|
| Accuracy | Answers come from your verified data, not AI imagination |
| Currency | Update your documents, and AI answers update automatically |
| Transparency | Can cite sources, allowing verification |
| Control | Your data stays yours—no need to retrain expensive models |
| Speed | Deploy in weeks, not months of model training |
Vector Databases vs. Traditional Databases
Understanding when to use what:
| Scenario | Best Choice | Why |
|---|---|---|
| Customer transactions, orders, invoices | Traditional database | Structured data, exact lookups, ACID compliance |
| Inventory counts, financial records | Traditional database | Precise numbers, relational queries |
| "Find documents about project management best practices" | Vector database | Meaning-based search across unstructured content |
| "Show products similar to this one" | Vector database | Conceptual similarity, not exact attributes |
| Customer profile data | Traditional database | Structured attributes, exact retrieval |
| "What does our policy say about remote work?" | Vector database | Semantic search across documents |
| Reporting and analytics | Traditional database | Aggregations, joins, structured queries |
| AI-powered recommendations | Vector database | Understanding relationships and preferences |
The reality: Most businesses will use both. Traditional databases for structured operations, vector databases for AI-powered experiences. Many modern databases now offer both capabilities.
Popular Vector Database Options
For businesses exploring this space, here are the leading options:
Fully Managed (Cloud-Hosted)
Pinecone
- Easiest to start with, no infrastructure management
- Automatic scaling, high performance
- Starting around USD 70/month for production workloads
- Best for: Teams wanting simplicity and speed to deployment
Weaviate Cloud
- Strong hybrid search (combining keyword and vector)
- Built-in AI integrations
- Good for: Organizations needing flexible search capabilities
Open Source (Self-Hosted)
Milvus
- Handles massive scale (billions of vectors)
- Widely adopted, strong community
- Good for: Organizations with technical teams and scale requirements
Chroma
- Lightweight, developer-friendly
- Excellent for prototyping and smaller applications
- Good for: Getting started, experiments, smaller deployments
Built Into Existing Databases
PostgreSQL with pgvector
- Add vector capabilities to existing PostgreSQL databases
- Familiar tools and infrastructure
- Good for: Organizations already using PostgreSQL
MongoDB Atlas Vector Search
- Vector search within MongoDB
- Combines document and vector databases
- Good for: Existing MongoDB users
Oracle AI Vector Search, Azure AI Search
- Enterprise options from major vendors
- Integration with existing enterprise infrastructure
- Good for: Organizations with established vendor relationships
Getting Started: A Practical Approach
You don't need to overhaul your infrastructure overnight. Here's a sensible path forward:
Phase 1: Identify the Opportunity
Ask yourself:
Where does keyword search fail your business?
- Customer support searching knowledge bases
- Employees finding internal documentation
- Customers discovering products
- Content teams locating assets
Where would "understanding meaning" help?
- AI chatbot accuracy
- Recommendation relevance
- Duplicate content identification
- Similar case/issue finding
Phase 2: Start with a Pilot
Choose a bounded use case:
- Internal knowledge search for one department
- Customer FAQ chatbot for common questions
- Product similarity for one category
- Document discovery for one content type
Use a managed service (like Pinecone) to minimize infrastructure complexity. Focus on proving value, not building perfect systems.
Phase 3: Measure and Expand
Track meaningful metrics:
- Search success rate (did users find what they needed?)
- Time to information (how long to find answers?)
- Chatbot accuracy (correct responses vs. hallucinations?)
- User satisfaction (qualitative feedback?)
If the pilot succeeds, expand to additional use cases with proven patterns.
Phase 4: Build the Foundation
As vector capabilities prove valuable:
- Evaluate whether managed or self-hosted fits your needs
- Consider how vectors integrate with existing data infrastructure
- Develop internal expertise and best practices
- Plan for scale based on actual usage patterns
Questions Business Leaders Should Ask
When evaluating vector database initiatives:
Strategic Questions
- What business problem are we solving? (Not "how do we use this technology?")
- Where does our current search/discovery experience fail?
- What would better understanding of meaning enable?
- How does this fit our AI and data strategy?
Technical Questions (For Your Team)
- What's the volume of content we need to handle?
- How frequently does our content change?
- What latency is acceptable for our use case?
- How does this integrate with our existing systems?
Vendor Questions
- How is pricing structured? (Query volume? Storage? Both?)
- What happens if we need to scale significantly?
- What embedding models are supported?
- How do we migrate data if we change providers?
- What enterprise features exist? (Security, compliance, audit logs)
Common Misconceptions
"Vector databases replace traditional databases"
Reality: They complement each other. You still need relational databases for transactions, structured data, and precise queries. Vector databases add a new capability—meaning-based search—they don't eliminate the need for existing infrastructure.
"This is only for tech companies"
Reality: Any business with content, customers, or knowledge can benefit. Retailers use them for product discovery. Healthcare organizations search medical literature. Law firms find relevant case precedents. Financial services detect fraud. The applications span every industry.
"We need a data science team to use vector databases"
Reality: Modern vector databases are increasingly accessible. Managed services handle complexity. Pre-built integrations with AI tools reduce custom development. Many organizations start with small technical teams and limited AI expertise.
"It's too expensive for our scale"
Reality: Managed services start at accessible price points. Open-source options exist for those with technical resources. The cost is often recovered quickly through improved efficiency and better customer experiences.
"Our data isn't ready"
Reality: You probably have more usable content than you think—documents, FAQs, product descriptions, support tickets. Start with what you have; perfect data organization isn't a prerequisite.
The Bigger Picture: Why This Technology Matters
Vector databases represent a fundamental shift in how computers understand information.
For decades, software has required humans to adapt to machine limitations—using exact keywords, structured queries, and precise terminology. Vector databases flip this relationship. Now machines can understand human intent, finding what we mean even when we don't express it perfectly.
This shift enables:
More natural interactions — Ask questions the way you'd ask a colleague, not the way a search engine requires.
Smarter AI applications — Give AI access to your specific knowledge, not just generic training data.
Better discovery — Find relevant information you didn't know existed because it didn't match your keywords.
Institutional knowledge preservation — Capture and retrieve organizational wisdom that would otherwise be lost in unsearchable formats.
As AI becomes central to business operations, vector databases become essential infrastructure—the foundation that allows AI to actually understand and work with your data.
Frequently Asked Questions
What's the difference between a vector database and regular AI like ChatGPT?
ChatGPT and similar AI models generate responses based on their training data. Vector databases store and search your specific data. They work together: the vector database finds relevant information from your content, then the AI uses that information to generate accurate responses. Think of ChatGPT as the brain that can think and communicate, and the vector database as the memory that stores your specific knowledge.
How much does a vector database cost?
Costs vary widely based on scale and approach. Managed services like Pinecone start around USD 70/month for production use. Open-source options are free but require infrastructure and expertise. Enterprise deployments with billions of vectors and high performance requirements cost significantly more. Most businesses start small and scale based on proven value.
Do we need to change our existing systems?
Not necessarily. Vector databases typically integrate alongside existing infrastructure. Many traditional databases now offer vector extensions, allowing you to add capabilities without wholesale changes. The integration approach depends on your specific use case and existing technology stack.
How long does implementation take?
A pilot project using managed services can launch in weeks. Production deployments with proper integration typically take 2-4 months. Enterprise-wide rollouts with multiple use cases may span 6-12 months. Start focused, prove value, then expand.
Is our data safe in a vector database?
Vector databases offer security features comparable to traditional databases—encryption, access controls, audit logging. Managed cloud providers meet enterprise security and compliance standards. Self-hosted options keep data entirely within your control. Evaluate security like you would any data system.
What happens to the original content?
The original content remains intact. Vector databases store mathematical representations (vectors) of your content, typically alongside references to the originals. When a search returns results, you retrieve the actual documents, images, or other content—the vectors just enabled finding them.
Ready to Make AI Work with Your Data?
Vector databases are the bridge between powerful AI capabilities and your specific business knowledge. Without them, AI applications are generic and prone to errors. With them, AI becomes genuinely useful—grounded in your data, accurate about your business, and valuable to your operations.
Here's How DSRPT Can Help:
🔍 AI Readiness Assessment We'll evaluate your data landscape, identify high-value use cases, and map a practical path to AI-powered search and discovery.
🤖 AI Chatbot Development Build customer-facing or internal chatbots that actually understand your business—powered by your documents, policies, and knowledge bases using RAG architecture.
Explore AI Chatbot Solutions →
🔎 Enterprise Search Implementation Transform how your organization finds information with semantic search that understands meaning, not just keywords.
Improve Your Enterprise Search →
💬 Quick Conversation Not sure where to start? We're happy to discuss your challenges and explore whether vector database technology makes sense for your situation.
Why DSRPT?
We work with businesses across Kuwait, the GCC, and Australia—organizations navigating the practical realities of AI adoption. As Google Premier Partners with deep technical expertise, we translate emerging technology into business results.
Our approach:
- Business-first: Technology serves strategy, not the other way around
- Practical implementation: Working solutions, not theoretical possibilities
- Knowledge transfer: Your team learns alongside the project
The companies getting ahead with AI aren't waiting for perfect conditions—they're starting with focused pilots, proving value, and building from there.